“快餐式科研”,指仅通过对公共数据库进行快速检索便能拼凑论文的研究行为,已成为全球学术出版界共同关注的焦点。此类研究往往仓促完成,导致大量低质量、重复性的成果涌入学术期刊。最新预印本《生成式人工智能时代下重复性出版物的激增》(Dramatic increase in redundant publications in the Generative AI era, doi: https://doi.org/10.1101/2025.09.09.25335401) 深刻揭示了这一问题的严重性。

预印本揭示了科研诚信问题爆发的迅猛态势,强调了具备灵活、专业的科研诚信团队的必要性。2024 年,当重复论文数量出现 400% 的暴涨时,学术界尚未建立起有效的论文重复性审查机制,而生成式人工智能的广泛应用,更进一步加剧了论文数量的非理性增长,这些问题至今仍是出版机构面临的重大挑战。
Frontiers 的应对策略
Frontiers 率先采取了行动。2024 年年中,Frontiers 观察到孟德尔随机化研究(MR)的投稿量出现激增,紧接着是大量基于美国国家健康与营养调查(NHANES)数据库的投稿。2025 年 2 月,佛罗里达大学教授、Frontiers in Family Medicine and Primary Care 期刊主编 Arch G. Mainous III 教授一针见血地指出了核心问题:大规模数据集包含无数变量组合,若缺乏明确的理论假设,纯粹由数据驱动得出的统计显著性可能完全源于偶然。
“这些数据库本是许多重要研究和流行病学评估的基石,但问题在于,海量的变量使得某些研究团队能够构建变量矩阵,轻易地寻找统计显著性来制造关联。这类研究最缺乏的是一个具有明确预期结果的科学假设。另外,任何假设都需充分考虑 NHANES 等数据集的背景因素,并在将结论应用于其他人群或者地区时,进行必要的调整。”
Mainous 博士强调,虽然这些数据库推动了不少有意义的研究,但如果缺乏明确的研究问题和对背景的深入理解,作者实际上只是在数据中盲目地搜寻规律。
为此,Frontiers 迅速响应,要求相关投稿必须以可检验、循证的假设为基础。新政策规定,作者需提供外部实验验证或来自其所在机构的数据,以确保每篇投稿都能超越公共数据集的局限,从而提供独特的学术价值。需要注意的是,Spick 等人发表的预印本中,引用的所有论文均在这一政策实施前发表,不符合当前标准。
划定明确底线
2024 年 7 月,Frontiers 成为最早强制要求 MR 研究提供独立外部验证的出版机构之一。所有缺乏实验验证或机构数据的 MR 稿件将在初审阶段被拒稿。这项政策效果立竿见影:首月 MR 投稿量下降 61%,至今累计降幅超过 70%。
严格的筛查也显著减少了 NHANES 相关的投稿,但此类研究数量在 2025 年仍持续增长。今年初,Frontiers 成为首家明确规定所有基于简单查询公共数据的论文(包括 NHANES 研究)都必须提供外部验证的出版机构,并向作者和审稿人明确传达“每篇论文必须贡献独特科学价值”的要求。自强化政策实施以来,Frontiers 已拒绝:
- 5,513 项孟德尔随机化研究(自 2024 年 7 月起);
- 1,382 篇基于 NHANES 的投稿(自 2025 年 5 月起)。
这项政策的具体影响如下表所示:
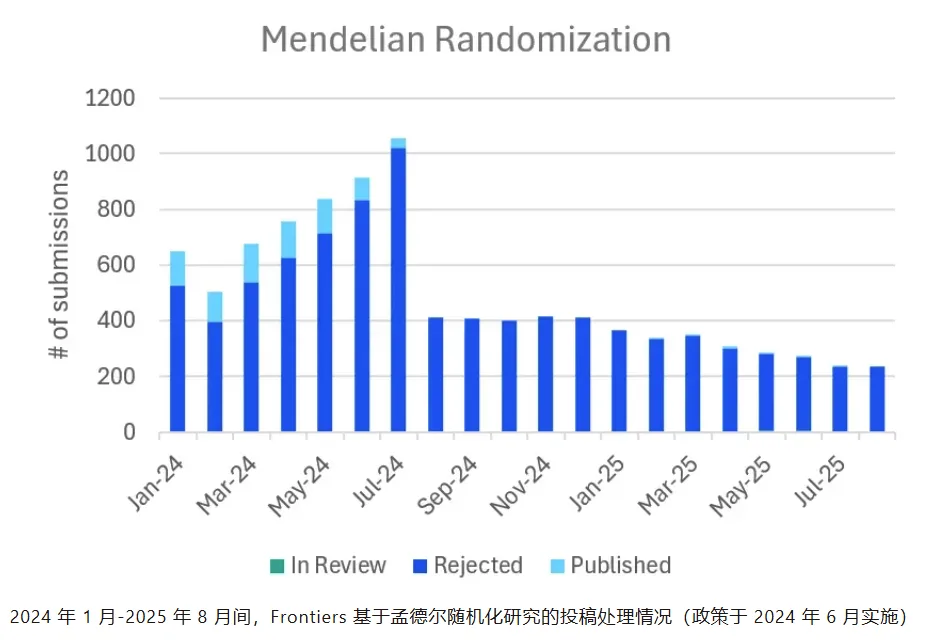
2024 年 1 月-2025 年 8 月间,Frontiers 基于孟德尔随机化研究的投稿处理情况(政策于 2024 年 6 月实施)
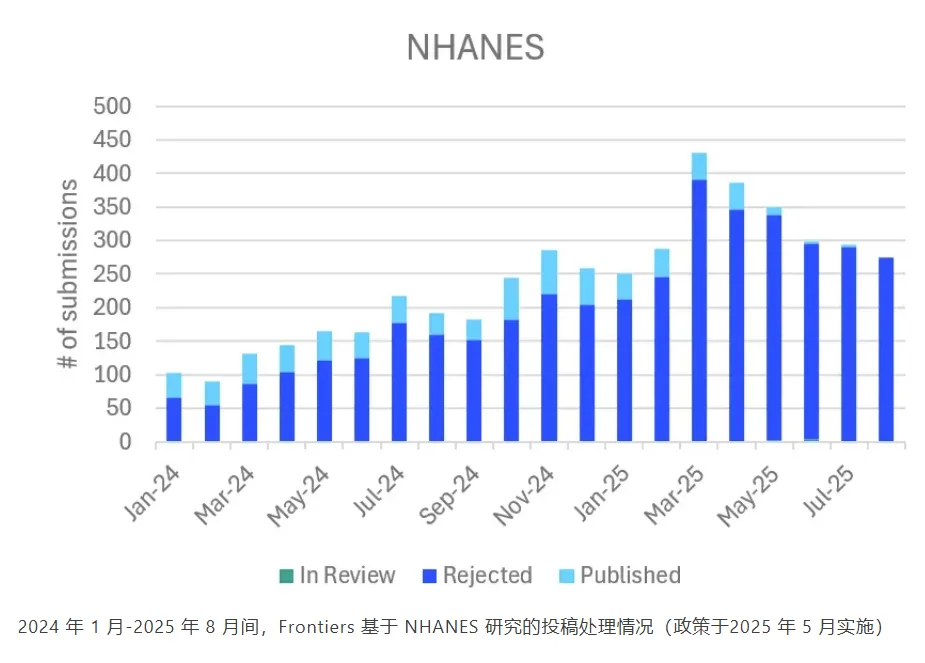
2024 年 1 月-2025 年 8 月间,Frontiers 基于 NHANES 研究的投稿处理情况(政策于2025 年 5 月实施)
AI时代的科研诚信:
技术赋能与专家智慧并重

Frontiers 对开篇提到的预印本文章表示欢迎,并正在与作者联系以交流意见。在 2025 年 2 月的一篇社论中,Arch G. Mainous III 博士还深入分析了“论文工厂”如何利用 NHANES 等大型公共数据库,通过操纵数据,批量生产欺诈性论文并售卖给作者,而这极大增加了编辑与审稿人的负担:
“遗憾的是,这些科学上存疑,但具有统计显著性的关系,已经成为论文工厂生产并售卖稿件的基础。只要存在统计显著性,就更容易发表。值得注意是,只要进行足够多的变量比较,即使是纯属偶然也会出现统计显著性,而这会导致论文数量激增,令期刊编辑和审稿人不堪重负。”
Mainous 博士一语道破了关键风险:大规模数据集可能产生毫无实际意义却“显著”的关联,唯有严格评审才能去伪存真。
为应对这一威胁,Frontiers 多管齐下:人工智能评审助手(AIRA)可自动检测每篇投稿的二十多项诚信指标,包括专门识别“论文工厂”的十余项特征数据,并标记供人工复核。任何异常信号都会触发由六十余位科研诚信专家、专业编辑和审稿人组成的团队进行深度评估。他们以科学价值为核心评判标准,而非仅仅依赖统计概率。Frontiers还与两家领先的外部问题内容检测机构Cactus Communications和Clear Skies合作,并将其工具整合至审稿流程中。
Frontiers 这项政策不仅仅是“过滤稿件”,每篇拒稿均附有详细的反馈,以帮助作者提升研究质量,进而更好地满足严格的学术标准。同时,科研诚信团队还积极与其他出版与资助机构协同交流,共同筑牢学术防线。正如科研诚信项目经理 Simone Ragavooloo 所言:
“这一现象并非仅涉及论文工厂,实际上也有不少作者出于无心,试图在重视产量与影响力的体系内遵守规则,结果提交了技术合规但质量不高的稿件,破坏了学术信任。出版商必须对此做出回应,制定明确的政策,开展积极的引导,从而重新确立良好科学的标准。”
Frontiers 同时强调,不应将论文冗余问题简单归咎于 AI 本身。即将发布的调研显示,AI 正在被研究人员广泛且规范地使用,而当前要务是支持 AI 合理应用的同时,坚决杜绝“问题稿件”(无论是否是 AI 生成)发表。
Frontiers 通过健全的政策、先进的技术与积极的引导,坚定地维护科学记录的完整性。这充分体现出,科学合理的科研防线不仅无碍真正的创新研究,反而有助于推动开放数据的规范和有序应用。
